Goals of this course
This course gives an introduction to Spicy, a parser generator for network protocols and file formats which integrates seamlessly with Zeek. The course is complementary to the Spicy reference documentation and is intended to give a more guided (though selective and incomplete) tour of Spicy and its use with Zeek.
After this course you should be comfortable implementing protocol parsers specified in an RFC and integrate it with Zeek.
![]()
Why Spicy?
Historically extending Zeek with new parsers required interacting with Zeek's C++ API which was a significant barrier to entry for domain experts.
Spicy is a domain-specific language for developing parsers for network protocols or file formats which integrates well with Zeek.
Flexible multi-paradigm language
With Spicy parsers can be
expressed in declaratively in a format close to specifications, e.g., the
following TFTP ERROR message
# 2 bytes 2 bytes string 1 byte
# -----------------------------------------
# | Opcode | ErrorCode | ErrMsg | 0 |
# -----------------------------------------
can be expressed in Spicy as
type Error = unit {
op_code: uint16;
error_code: uint16;
msg: bytes &until=b"\x00";
};
Spicy supports procedural code which can be hooked into parsing to support more complex parsing scenarios.
function sum(a: uint64, b: uint64): uint64 { return a + b; }
type Fold = unit {
a: uint8;
b: uint8 &convert=sum(self.a, $$);
c: uint8 &convert=sum(self.b, $$);
};
Incremental parsing
The parsers generated by Spicy automatically support incremental parsing. Data can be fed as it arrives without blocking until all data is available. Hooks allow reacting to parse results.
Built-in safety
Spicy code is executed safely so many common errors are rejected, e.g.,
- integer under- or overflows
- incorrect use of iterators
- unhandled switch cases
Integration into Zeek
Spicy parsers can trigger events in Zeek. Parse results can transparently be made available to Zeek script code.
Prerequisites
To follow this course, installing recent versions of Zeek and Spicy is required (at least zeek-8.0 and spicy-1.14). The Zeek documentation shows the different ways Zeek can be installed.
In addition we require:
- a text editor to write Spicy code
- a C++ compiler to compile Spicy code and Zeek plugins
- CMake for developing Zeek plugins with Spicy
- development headers for
libpcapto compile Zeek plugins
Docker images
The Zeek project provides Docker images.
Zeek playground
A simplified approach for experimentation is to use the Zeek playground repository which offers an environment integrated with Visual Studio Code. Either clone the project and open it locally in Visual Studio Code and install the recommended plugins, or open it directly in a Github Codespace from the Github repository view.
A note on exercise hints and solutions
We include hints or solutions for many exercises. By default they are displayed, but in collapsed form.
If you would prefer even less temptation they can be toggled completely by pressing F10 (try it now).
Spicy language
This chapter gives a coarse overview over the Spicy language.
We show a selection of features from the Spicy reference documentation, in particular
In terms of syntax Spicy borrows many aspects from C-like languages.
Hello world
# hello.spicy
module hello;
print "Hello, world!";
- every Spicy source file needs to declare the module it belongs to
- global statements are run once when the module is initialized
Compile and run this code with
$ spicyc -j hello.spicy
Hello, world!
Here we have used Spicy's
spicyc
executable to compile and immediately run the source file hello.spicy.
Most commands which compile Spicy code support -d to build parsers in debug
mode. This is often faster than building production code and useful during
parser development.
$ spicyc -j -d hello.spicy
Hello, world!
Basic types
All values in Spicy have a type.
While in some contexts types are required (e.g., when declaring types, or function signatures), types can also be inferred (e.g., for variable declarations).
global N1 = 0; # Inferred as uint64.
global N2: uint8 = 0; # Explicitly typed.
# Types required in signatures, here: `uint64` -> `void`
function foo(arg: int64) {
local inc = -1; # Inferred as int64.
print arg + inc;
}
Spicy provides types for e.g.,
- integers, booleans
- optional
- bytes, string
- tuples and containers
- enums, structs
- special purpose types for e.g., network address, timestamps, or time durations
See the documentation for the full list of supported types and their API.
Boolean and integers
Boolean
Booleans
have two possible values: True or False.
global C = True;
if (C)
print "always runs";
Integers
Spicy supports both signed and unsigned integers with widths of 8, 16, 32 and 64 bits:
uint8,uint16,uint32,uint64int8,int16,int32,int64
Integers are checked at both compile and runtime against overflows. They are either statically rejected or trigger runtime exceptions.
Integer literals without sign like e.g., 4711 default to uint64; if a sign
is given int64 is used, e.g., -47, +12.
If permitted integer types convert into each other when required; for cases
where this is not automatically possible one can explicitly cast integers to
each other:
global a: uint8 = 0;
global b: uint64 = 1;
# Modify default: uint8 + uint64 -> uint64.
global c: uint8 = a + cast<uint8>(b);
Optional
Optionals either contain a value or nothing. They are a good choice when one wants to denote that a value can be absent.
optional is a parametric (also sometimes called generic) type in that it
wraps a value of some other type.
global opt_set1 = optional(4711);
global opt_set2: optional<uint64> = 4711;
global opt_unset: optional<uint64>;
Optionals implicitly convert to booleans. This can be used to check whether they are set.
assert opt_set1;
assert ! opt_unset;
Assigning Null to an optional empties it.
global x = optional(4711);
assert x;
x = Null;
assert ! x;
To extract the value contained in an optional dereference it with the * operator.
global x = optional(4711);
assert *x == 4711;
Bytes and strings
The bytes
type
represents raw bytes, typically from protocol data. Literals for bytes are
written with prefix b, e.g., b"\x00byteData\x01".
The string
type
represents text in a given character set.
Conversion between bytes and string are always explicit, via bytes'
decode
method
or string's
encode,
e.g.,
global my_bytes = b"abc";
global my_string = "abc";
global my_other_string = my_bytes.decode(); # Default: UTF-8.
print my_bytes, my_string, my_other_string;
bytes can be iterated over.
for (byte in b"abc") {
print byte;
}
Use the format operator
%
to compute a string representation of Spicy values. Format strings roughly follow the
POSIX format string
API.
global n = 4711;
global s = "%d" % n;
The format operator can be used to format multiple values.
global start = 0;
global end = 1024;
print "[%d, %d)" % (start, end);
Collections
Tuples
Tuples are heterogeneous collections of values. Tuple values are immutable.
global xs = (1, "a", b"c");
global ys = tuple(1, "a", b"c");
global zs: tuple<uint64, string, bytes> = (1, "a", b"c");
print xs, ys, zs;
Individual tuple elements can be accessed with subscript syntax.
print (1, "a", b"c")[1]; # Prints "a".
Optionally individual tuple elements can be named, e.g.,
global xs: tuple<first: uint8, second: string> = (1, "a");
assert xs[0] == xs.first;
assert xs[1] == xs.second;
Containers
Spicy provides data structures for lists
(vector),
and associative containers
(set,
map).
The element types can be inferred automatically, or specified explicitly. All of the following forms are equivalent:
global a1 = vector(1, 2, 3);
global a2 = vector<uint64>(1, 2, 3);
global a3: vector<uint64> = vector(1, 2, 3);
global b1 = set(1, 2, 3);
global b2 = set<uint64>(1, 2, 3);
global b3: set<uint64> = set(1, 2, 3);
global c1 = map("a": 1, "b": 2, "c": 3);
global c2 = map<string, uint64>("a": 1, "b": 2, "c": 3);
global c3: map<string, uint64> = map("a": 1, "b": 2, "c": 3);
All collection types can be iterated.
for (x in vector(1, 2, 3)) {
print x;
}
for (x in set(1, 2, 3)) {
print x;
}
# Map iteration yields a (key, value) `tuple`.
for (x in map("a": 1, "b": 2, "c": 1)) {
print x, x[0], x[1];
}
Indexing into collections and iterators is checked at runtime.
Use |..| like in Zeek to obtain the number of elements in a collection, e.g.,
assert |vector(1, 2, 3)| == 3;
To check whether a set or map contains a given key use the in operator.
assert 1 in set(1, 2, 3);
assert "a" in map("a": 1, "b": 2, "c": 1)
User-defined types
Enums and structs are user-defined data types which allow you to give data semantic meaning.
Enums
Enumerations map integer values to a list of labels.
By default enum labels are numbered 0, ...
type X = enum { A, B, C, };
local b: X = X(1); # `X::B`.
assert 1 == cast<uint64>(b);
One can override the default label numbering.
Providing values for either all or no labels tends to lead to more maintainable code. Spicy still allows providing values for only a subset of labels.
type X = enum {
A = 1,
B = 2,
C = 3,
};
By default enum values are initialized with the implicit Undef label.
type X = enum { A, B, C, };
global x: X;
assert x == X::Undef;
If an enum value is constructed from an integer not corresponding to a label, an implicit label corresponding the numeric value is used.
type X = enum { A, B, C, };
global x = X(4711);
assert cast<uint64>(x) == 4711;
print x; # `X::<unknown-4711>`.
Structs
Structs are similar to tuples but mutable.
type X = struct {
a: uint8;
b: bytes;
};
Structs are initialized with Zeek record syntax.
global x: X = [$a = 1, $b = b"abc"];
Struct fields can be marked with an &optional attribute to denote optional
fields. The ?. operator can be used to query whether a field was set.
type X = struct {
a: uint8;
b: uint8 &optional;
c: uint8 &optional;
};
global x: X = [$a = 47, $b = 11];
assert x?.a;
assert x?.b : "%s" % x;
assert ! x?.c : "%s" % x;
Additionally, one can provide a &default value for struct fields to denote a
value to use if none was provided on initialization. Fields with a &default
are always set.
type X = struct {
a: uint8;
b: uint8 &default=11;
c: bytes &optional &default=b"abc";
};
global x: X = [$a = 47];
assert x.b == 11;
assert x.c;
Exercises
-
What happens at compile time if you try to create a
uint8a value outside of its range, e.g.,uint8(-1)oruint8(1024)? -
What happens at runtime if you perform an operation which leaves the domain of an integer value, e.g.,
global x = 0; print x - 1; global y: uint8 = 255; print y + 1; global z = 1024; print cast<uint8>(z); print 4711/0; -
What happens at compile time if you access a non-existing tuple element, e.g.,
global xs = tuple(1, "a", b"c"); print xs[4711]; global xs: tuple<first: uint8, second: string> = (1, "a"); print xs.third; -
What happens at runtime if you try to get a non-existing
vectorelement, e.g.,print vector(1, 2, 3)[4711]; -
What happens at runtime if you try to dereference an invalidated iterator, e.g.,
global xs = vector(1); global it = begin(xs); print *it; xs.pop_back(); print *it; -
Can you dereference a collection's
enditerator? -
What happens at runtime if you dereference an unset
optional?
Variables
Variables in Spicy can either be declared at local or module (global) scope.
Local variables live in bodies of functions. They are
declared with the local storage qualifier and always mutable.
function hello(name: string) {
local message = "Hello, %s" % name;
print message;
}
Global variables live at module scope. If declared with global they are
mutable, or immutable if declared with const.
module foo;
global N = 0;
N += 1;
const VERSION = "0.1.0";
Conditionals and loops
Conditionals
if/else
Spicy has if
statements
which can optionally contain else branches.
global x: uint64 = 4711;
if (x > 100) {
print "%d > 100" % x;
} else if (x > 10) {
print "%d > 10" % x;
} else if (x > 1) {
print "%d > 1" % x;
} else {
print x;
}
switch
To match a value against a list of possible options the switch
statement
can be used.
type Flag = enum {
OFF = 0,
ON = 1,
};
global flag = Flag::ON;
switch (flag) {
case Flag::ON: print "on";
case Flag::OFF: print "off";
default: print "???";
}
In contrast to its behavior in e.g., C, in Spicy
- there is no fall-through in
switch, i.e., there is an implicitbreakafter eachcase, switchcases are not restricted to literal integer values; they can contain any expression,- if no matching
caseordefaultis found, a runtime error is raised.
Loops
Spicy offers two loop constructs:
global xs = vector("a", "b", "c");
for (x in xs)
print x;
global i = 0;
while (i < 3) {
print i;
++i;
}
Functions
Functions in Spicy look like this:
function make_string(x: uint8): string {
return "%d" % x;
}
Functions without return value can either be written without return type, or
returning void.
function nothing1() {}
function nothing2(): void {}
By default function arguments are passed as read-only references. To instead
pass a mutable value declare the argument inout.
function barify(inout x: string) {
x = "%s bar" % x;
}
global s = "foo";
assert s == "foo";
barify(s);
assert s == "foo bar";
Exercises
-
Write a function computing values of the Fibonacci sequence, i.e., a function
function fib(n: uint64): uint64 { ... }- if
n < 2returnn - else return
fib(n - 1) + fib(n - 2)
For testing you can
assert fib(8) == 21;.Solution
function fib(n: uint64): uint64 { if (n < 2) return n; # This runs iff above `if` condition was false, but in this case could also be written # as an `else` branch. return fib(n - 1) + fib(n - 2); } - if
-
Add memoization to your
fibfunction. For that change its signature tofunction fib(n: uint64, inout cache: map<uint64, uint64>): uint64 { ... }This can then be called like so:
global m_fib: map<uint64, uint64>; fib(64, m_fib);For testing you can
assert fib(64, m_fib) == 10610209857723;.Solution
function fib(n: uint64, inout cache: map<uint64, uint64>): uint64 { # If the value is already in the cache we do not need to compute it. if (n in cache) return cache[n]; # Value was not in the cache. Compute its value and store it. local r = 0; if (n < 2) r = n; else # Here we want an `else` branch for sure. We need to pass the cache # down to other invocations. Since the passing happens by reference all # invocations share a cache. r = fib(n - 1, cache) + fib(n - 2, cache); # Persist result in cache. cache[n] = r; # Return the result. return r; } -
Try modifying your
fibfunctions so users do not have to provide the cache themselves.Hint
You want to store the cache somewhere yourself and provide users with a wrapped function which implicitly uses your cache.
There are two places to put the cache:
- Construct the cache as a local variable inside the body of your wrapper function. With this different invocations of the wrapper function would not share the same cache which can be useful in certain scenarios.
- Alternatively one could store the cache in a
global.
Modules revisited
Every Spicy file specifies the module it declares.
module foo;
Other modules can be imported with the import
keyword.
Typically, to refer to a type, function or variable in another module, it needs to be declared public.
# file: foo.spicy
module foo;
public global A = 47;
public const B = 11;
const C = 42;
# file: bar.spicy
module bar;
import foo;
print foo::A, foo::B;
# Rejected: 'foo::C' has not been declared public
# print foo::C;
Declaring something public makes it part of the external API of a module.
This makes certain optimizations inapplicable (e.g., dead code removal).
Only declare something public if you intend it to be used by other modules.
With spicy-1.11 (shipping with zeek-7) the rules around public are much more
relaxed and public even closer maps onto "exposed C++ API". Above example use
of a non-public const would be accepted.
Parsing
Parsing in
Spicy
is centered around the unit type which in many ways looks similar to a
struct type.
A unit declares an ordered list of fields which are parsed from the input.
If a unit is public it can serve as a top-level entry point for parsing.
module foo;
public type Foo = unit {
version: uint32;
on %done { print "The version is %s." % self.version; }
};
- The parser for
Fooconsists of a single parser which extracts anuint32with the default network byte order. - The extracted
uint32is bound to a named field to store its value in the unit. - We added a unit hook which runs when the parser is done.
We can run that parser by using a driver which feeds it input (potentially incrementally).
$ printf '\x00\x00\x00\xFF' | spicy-driver -d hello.spicy
The version is 255.
We use
spicy-driver
as driver. It reads input from its stdin and feeds it to the parser, and
executes hooks.
Another driver is
spicy-dump
which prints the unit after parsing. Zeek includes its own dedicated driver for
Spicy parsers.
The major differences to struct are:
unitfields need to have a parsable type,- by default all
unitfields are&optional, i.e., aunitvalue can have any or all fields unset.
Structure of a parser
A parser contains a potentially empty ordered list of subparsers which are invoked in order.
type Version = unit {
major: uint32;
minor: uint32;
patch: uint32;
};
# 4 bytes 4 bytes 4 bytes
# -----------------------------
# | Major | Minor | Patch |
# -----------------------------
#
# Figure 47-11: Version packet
Attributes
The behavior of individual subparsers or units can be controlled with attributes.
type Version = unit {
major: bytes &until=b".";
minor: bytes &until=b".";
patch: bytes &eod;
} &convert="v%s.%s.%s" % (self.major, self.minor, self.patch);
There are a wide range of both generic and type-specific attributes, e.g.,
- the
&sizeand&max-sizeattributes to control how much data should be parsed, - attributes
&parse-fromand&parse-atallowing to change where from where data is parsed, &convertto transform the value and/or type of parsed data, or&requiresto enforce post conditions.
Type-specific attributes are documented together with their type.
Extracting data without storing it
If one needs to extracted some data but does not need it one can declare an
anonymous
field
(without name) to avoid storing it. With >=spicy-1.9.0 (>=zeek-6.1.0) one
additionally can explicitly skip over input
data.
# Parser for a series of digits. When done parsing yields the extracted number.
type Number = unit {
n: /[[:digit:]]+/;
} &convert=self.n;
public type Version = unit {
major: Number;
: b".";
minor: Number;
: skip b".";
patch: Number;
};
Hooks
We can hook into parsing via unit or field hooks.
In hooks we can refer to the current unit via self, and the current field via
$$. We can declare multiple hooks for the same field/unit, even in multiple
files.
public type X = unit {
x: uint8 { print "a=%d" % self.x; }
on %done { print "X=%s" % self; }
};
on X::x {
print "Done parsing a=%d" % $$;
}
Conditional parsing
During parsing we often want to decide at runtime what to parse next, e.g., certain fields might only be set if a previous field has a certain value, or the type for the next field might be known dynamically from a previous field.
We can specify that a field should only be parsed if a condition is met.
type Integer = unit {
width: uint8 &requires=($$ != 0 && $$ < 5);
u8 : uint8 if (self.width == 1);
u16: uint16 if (self.width == 2);
u32: uint32 if (self.width == 3);
u64: uint64 if (self.width == 4);
};
Alternatively we can express this with a unit switch statement.
type Integer = unit {
width: uint8 &requires=($$ != 0 && $$ < 5);
switch (self.width) {
1 -> u8: uint8;
2 -> u16: uint16;
3 -> u32: uint32;
4 -> u64: uint64;
};
};
In both cases the unit will include all fields, both set and unset. Once can
query whether a field has been set with
?.,
e.g.,
on Integer::%done {
if (self?.u8) { print "u8 was extracted"; }
}
Often parsing requires examining input and dynamically choosing a matching parser from the input. Spicy models this with lookahead parsing which is explained in a separate section.
Controlling byte order
The used byte order can be controlled on the module, unit, or field level.
# The 'ByteOrder' type is defined in the built-in Spicy module.
import spicy;
# Switch default from network byte order to little-endian for this module.
%byte-order=spicy::ByteOrder::Little;
# This unit uses big byte order.
type X = unit {
# Use default byte order (big).
a: uint8;
# Use little-endian byte order for this field.
b: uint8 &byte-order=spicy::ByteOrder::Little;
} &byte-order=spicy::ByteOrder::Big;
Parsing types
Spicy parsers are build up from smaller parsers, at the lowest level from basic types present in the input.
Currently Spicy supports parsing for the following basic types:
Fields not extracting any data can be marked void. They can still have hooks attached.
Since they are pervasive we give a brief overview for vectors here.
Parsing vectors
A common requirement is to parse vector of the same type, possibly of dynamic length.
To parse a vector of three integers we would write:
type X = unit {
xs: uint16[3];
};
If the number of elements is not known we can parse until the end of the input data. This will trigger a parse error if the input does not contain enough data to parse all elements.
type X = unit {
xs: uint16[] &eod;
};
If the vector is followed by e.g., a literal we can dynamically detect with lookahead parsing where the vector ends. The literal does not need to be a field, but could also be in another parser following the vector.
type X = unit {
xs: uint16[];
: b"\x00"; # Vector is terminated with null byte.
};
If the terminator is in the domain of the vector elements we can also use the
&until attribute.
type X = unit {
# Vector terminate with a null value
xs: uint8[] &until=$$==0;
};
If the vector elements require attributes themselves, we can pass them by grouping them with the element type.
type X = unit {
# Parse a vector of 8-byte integers less than 1024 until we find a null.
xs: (uint64 &requires=$$<1024)[] &until=$$==0;
};
Exercises: A naive CSV parser
Assuming the following simplified CSV format:
- rows are separated by newlines
b"\n" - individual columns are separated by
b"," - there are not separators anywhere else (e.g., no
,in quoted column values)
A sample input would be
I,a,ABC
J,b,DEF
K,c,GHI
When copying above data into a file, make sure it ends in a single newline. If you use the copy to clipboard button (upper right in snippet) the data should be copied correctly.
For testing you can use the -f flag to spicy-dump or spicy-driver to read
input from a file instead of stdin, e.g.,
spicy-driver csv_naive.spicy -f input.csv
-
Write a parser which extracts the bytes on each row into a vector.
Hint 1
You top-level parser should contain a vector of rows which has unspecified length.
Hint 2
Define a new parser for a row which parses
bytesuntil it finds a newline and consumes it.Solution
module csv_naive; public type CSV = unit { rows: Row[]; }; type Row = unit { data: bytes &until=b"\n"; }; -
Extend your parser so it also extracts individual columns (as
bytes) from each row.Hint
The
&convertattribute allows changing the value and/or type of a field after it has been extracted. This allows you to split the row data into columns.Is there a builtin function which splits your row data at a separator (consuming the iterator)? Functions on
bytesare documented here. You can access the currently extracted data via$$.Solution
module csv_naive; public type CSV = unit { rows: Row[]; }; type Row = unit { cols: bytes &until=b"\n" &convert=$$.split(b","); }; -
Without changing the actual parsing, can you change your grammar so the following output is produced? This can be done without explicit loops.
$ spicy-driver csv_naive.spicy -f input.csv [[b"I", b"a", b"ABC"], [b"J", b"b", b"DEF"], [b"K", b"c", b"GHI"]]Hint 1
You could add a unit hook for your top-level unit which prints the rows.
on CSV::%done { print self.rows; }Since
rowsis a vector of units you still need to massage its data though ...Hint 2
You can use a unit
&convertattribute on your row type to transform it to its row data.Solution
module csv_naive; public type CSV = unit { rows: Row[]; }; type Row = unit { data: bytes &until=b"\n" &convert=$$.split(b","); } &convert=self.data; on CSV::%done { print self.rows; }
Adding additional parser state
We might want to add additional state to parsers, e.g.,
- share or modify data outside of our parser, or
- to locally aggregate data while parsing.
Sharing state across multiple units in the same Zeek connection with unit contexts will be discussed separately in a later section.
Passing outside state into units
We might want to pass additional state into a unit, e.g., to parameterize the unit's behavior, or to give the unit access to external state. This can be accomplished with unit parameters.
type X = unit(init: uint64 = 64) {
var sum: uint64;
on %init { self.sum = init; }
: uint8 { self.sum += $$; }
: uint8 { self.sum += $$; }
: uint8 { self.sum += $$; }
on %done { print self.sum; }
};
A few things to note here:
- Unit parameter look a lot like function parameters to the unit.
- Unit parameters can have default values which are used if the parameter was not passed.
- We refer to unit parameters by directly using their name;
selfis not used.
Unit parameters can also be used to give a unit access to its parent units and their state.
public type X = unit {
var sum: uint8;
: (Y(self))[];
};
type Y = unit(outer: X) {
: uint8 { outer.sum += $$; }
};
Unit variables
Unit variables allow to add additional data to units. Their data can be accessed like other unit fields.
type X = unit {
var sum: uint8;
: uint8 { self.sum += $$; }
: uint8 { self.sum += $$; }
: uint8 { self.sum += $$; }
on %done { print self.sum; }
};
By default unit variables are initialized with the default value of the type,
e.g., for a uint8 with 0.
If you want to capture whether a unit variable (or any other variable) was set,
use a variable of optional type instead of a dummy value.
To use with a different value, assign the variable in the unit's %init hook,
e.g.,
on %init { self.sum = 100; }
Lookahead parsing
Lookahead parsing is a core Spicy concept. Leveraging lookahead makes it possible to build concise grammars which remain comprehensible and maintainable as the grammar grows.
Deep dive: Parsing of vector of unknown size
We have already seen how we can use lookahead parsing to dynamically detect the length of a vector.
type X = unit {
: (b"A")[]; # Extract unknown number of literal 'A' bytes.
x: uint8;
};
We can view the generated parser by requesting grammar debug output from Spicy's
spicyc compiler.
$ spicyc -D grammar x.spicy -o /dev/null -p
# ~~~~~~~~~~ ~~~~~~~ ~~~~~~~~~~~~ ~~
# | | | |
# | | | - emit generated IR
# | | |
# | | - redirect output of generated code to /dev/null
# | |
# | - compile file 'x.spicy'
# |
# - emit 'grammar' debug stream to stderr
[debug/grammar] === Grammar foo::X
[debug/grammar] Epsilon: <epsilon> -> ()
[debug/grammar] While: anon -> while(<look-ahead-found>): anon_2 [field: anon (*)] [item-type: vector<bytes>] [parse-type: vector<bytes>]
[debug/grammar] Ctor: anon_2 -> b"A" (bytes) (container 'anon') [field: anon_2 (*)] [item-type: bytes] [parse-type: bytes]
[debug/grammar] LookAhead: anon_l1 -> {uint<8> (not a literal)}: <epsilon> | {b"A" (bytes) (id 1)}: anon_l2
[debug/grammar] Sequence: anon_l2 -> anon_2 anon_l1
[debug/grammar] (*) Unit: foo_X -> anon x
[debug/grammar] Variable: x -> uint<8> [field: x (*)] [item-type: uint<8>] [parse-type: uint<8>]
[debug/grammar]
[debug/grammar] -- Epsilon:
[debug/grammar] anon = true
[debug/grammar] anon_l1 = true
[debug/grammar] anon_l2 = false
[debug/grammar] foo_X = false
[debug/grammar]
[debug/grammar] -- First_1:
[debug/grammar] anon = { anon_2 }
[debug/grammar] anon_l1 = { anon_2 }
[debug/grammar] anon_l2 = { anon_2 }
[debug/grammar] foo_X = { anon_2, x }
[debug/grammar]
[debug/grammar] -- Follow:
[debug/grammar] anon = { x }
[debug/grammar] anon_l1 = { x }
[debug/grammar] anon_l2 = { x }
[debug/grammar] foo_X = { }
[debug/grammar]
In above debug output the entry point of the grammar is marked (*).
- parsing a unit consists of parsing the
anonfield (corresponding to the anonymous vector), andx - to parse the vector lookahead is used.
- lookahead inspects a
uint8(as epsilon) or literalb"A"
Types for lookahead
In addition to literals, lookahead also works with units which start with a literal. Spicy transparently detects such units and will use them for lookahead if possible.
Confirm this yourself by wrapping the literal in above unit in its own unit, and
validating by parsing an input like AAAAA\x01. Are there any major differences
in the generated grammar?
Using lookahead for conditional parsing
We have seen previously how we can use unit switch for conditional parsing.
Another instance of conditional parsing occurs when a protocol message
holds one of multiple possible sub-messages (a union). The sub-messages often
contain a tag to denote what kind of sub-message is transmitted.
With a unit switch statement we could model this like so.
public type X = unit {
tag: uint8;
switch (self.tag) {
1 -> m1: Message1;
2 -> m2: Message2;
* -> : skip bytes &eod; # For unknown message types simply consume all data.
};
};
type Message1 = unit {
payload: bytes &eod;
};
type Message2 = unit {
payload: bytes &eod;
};
The unit switch statement has a form without control variable which instead
uses lookahead. With this we can push parsing of the tag variable into the
units concerned with the particular messages so we keep all pieces related to a
particular message together.
public type X = unit {
switch {
-> m1: Message1;
-> m2: Message2;
-> : skip bytes &eod; # For unknown message types, simply consume all data.
};
};
type Message1 = unit {
: skip uint8(1);
payload: bytes &eod;
};
type Message2 = unit {
: skip uint8(2);
payload: bytes &eod;
};
Error recovery
Even with a grammar perfectly modelling a specification, parsing of real data can fail due to e.g.,
- endpoints not conforming to spec, or
- gaps in the input data due to capture loss.
Instead of altogether aborting parsing we would like to gracefully recover from parse errors, i.e., when the parser encounters a parse error we would like skip input until it can parse again.
Spicy includes support for expressing such recovery with the following model:
-
To resynchronize the input potential synchronization points are annotated, e.g., to synchronize input at the sequence
b"POST"the grammar might contain a field: b"POST" &synchronize;All constructs supporting lookahead parsing can be synchronization points, e.g., literals or fields with
unittype with a literal at a fixed offset. -
On a parse error the unit enters a synchronization trial mode.
Once the input could be synchronized a
%syncedhook is invoked. The implementation of the hook can examine the data up to the&synchronizefield, and eitherconfirmit to leave trial mode and continue normal parsing, orrejectit to look for a later synchronization point.
Exercises
Let's assume we are parsing a protocol where valid messages are always the
sequence AB, i.e., a the byte sequence b"AB". We will use the following
contrived grammar:
module foo;
public type Messages = unit {
: Message[];
};
type Message = unit {
a: b"A";
b: b"B";
};
on Message::%done { print self; }
-
Validate that this grammar can parse the input
ABABAB$ printf ABABAB | spicy-driver % [$a=b"A", $b=b"B"] [$a=b"A", $b=b"B"] [$a=b"A", $b=b"B"] -
What do you see if you pass misspelled input, like with the second
Achanged to1, i.e., the inputAB1BABWhy is this particular source range shown as error location?
Solution
[$a=b"A", $b=b"B"] [error] terminating with uncaught exception of type spicy::rt::ParseError: no expected look-ahead token found (foo.spicy:3:30-4:17)We first the result of parsing for the first
MessagefromAB, and encounter an error for the second element.The error corresponds to parsing the vector inside
Messages. The grammar expects eitherAto start a newMessage, or end of data to signal the end of the input;1matches neither so lookahead parsing fails. -
What are the potential synchronization points in this grammar we could use so we can extract the remaining data?
Solution
In this case parsing failed at the first field of
Message,Message::a. We coulda. synchronize on
Message::bby changing it tob: b"B" &synchronize;b. Synchronize on
Message::ain the next message, i.e., abandon parsing the remaining fields inMessageand start over. For that we would synchronize on the vector elements inMessages,: (Message &synchronize)[];A slight modification of this grammar seems to fail to synchronize and run into an edge case, https://github.com/zeek/spicy/issues/1594.
-
If you had to choose one, which one would you pick? What are the trade-offs?
Solution
-
If we synchronize on
Message::bit would seem that we should be able to recover at its data.This however does not work since the vector uses lookahead parsing, so we would fail already in
Messagesbefore we could recover inMessage. -
We need to synchronize on the next vector element.
In larger units synchronizing high up (e.g., on a vector in the top-level unit) allows recovering from more general errors at the cost of not extracting some data, e.g., we would be able to also handle misspelled
Bs in this example.
-
-
Add a single
&synchronizedattribute to the grammar so you can handle all possible misspellings. Also add a%syncedhook to confirm the synchronization result (on which unit?). Can you parse inputs like these?ABABAB AB1BAB A11BABYou can enable the
spicy-verbosedebug stream to show parsing progress.printf AB1BAB | HILTI_DEBUG=spicy-verbose spicy-driver -d foo.spicySolution
module foo; public type Messages = unit { : (Message &synchronize)[]; }; type Message = unit { a: b"A"; b: b"B"; }; on Message::%done { print self; } on Messages::%synced { confirm; }
Zeek integration
Zeek supports writing packet, protocol or file analyzers with Spicy. In addition to allowing inclusion of unmodified Spicy grammars, additional features include:
- automatic generation of Zeek analyzers from Spicy parsers from interface definition (EVT) files
- ability to trigger Zeek events from Spicy unit hooks,
- (automatic) exporting of types defined in Spicy as Zeek record types,
- a Spicy module to control Zeek from Spicy code.
Getting started
The recommended approach to integrate a Spicy parser with Zeek is to use the default Zeek package template.
We can create Zeek packet, protocol or file analyzers by selecting the appropriate template feature. E.g., to create a new Zeek package for a protocol analyzer and interactively provide required user variables,
zkg create --packagedir my_analyzer --features spicy-protocol-analyzer
zkg uses Git to track package information. When running in a VM, this can
cause issues if the package repository is in a mounted directory. If you run
into this trying creating the package in directory which is not mounted from the
host.
Use the template to create a Spicy protocol analyzer for analyzing TCP traffic now to follow along with later examples.
This will create a protocol analyzer from the template. Items which need to be
updated are marked TODO. It will generate e.g.,
zkg.meta: package metadata describing the package and setting up building and testinganalyzer/*.evt: interface definition for exposing Spicy parser as Zeek analyzer*.spicy: Spicy grammar of the parserzeek_*.spicy: Zeek-specific Spicy code
scripts/main.zeek: Zeek code for interacting with the analyzerdpd.sig: Signatures for dynamic protocol detection (DPD)
testing/tests: BTest test cases
You can use zkg to install the package into your Zeek installation.
zkg install <package_dir>
To run its tests, e.g., during development:
zkg test <package_dir>
The generated project uses CMake for building and BTest for testing. You can
build manually, e.g., during development. The test scaffolding assumes that the
CMake build directory is named build.
# Building.
mkdir build
(cd build && cmake .. && make)
# Testing.
(cd testing && btest)
We can show available template features with zkg template info.
$ zkg template info
API version: 1.0.0
features: github-ci, license, plugin, spicy-file-analyzer, spicy-packet-analyzer, spicy-protocol-analyzer
origin: https://github.com/zeek/package-template
provides package: true
user vars:
name: the name of the package, e.g. "FooBar" or "spicy-http", no default, used by package, spicy-protocol-analyzer, spicy-file-analyzer, spicy-packet-analyzer
namespace: a namespace for the package, e.g. "MyOrg", no default, used by plugin
analyzer: name of the Spicy analyzer, which typically corresponds to the protocol/format being parsed (e.g. "HTTP", "PNG"), no default, used by spicy-protocol-analyzer, spicy-file-analyzer, spicy-packet-analyzer
protocol: transport protocol for the analyzer to use: TCP or UDP, no default, used by spicy-protocol-analyzer
unit: name of the top-level Spicy parsing unit for the file/packet format (e.g. "File" or "Packet"), no default, used by spicy-file-analyzer, spicy-packet-analyzer
unit_orig: name of the top-level Spicy parsing unit for the originator side of the connection (e.g. "Request"), no default, used by spicy-protocol-analyzer
unit_resp: name of the top-level Spicy parsing unit for the responder side of the connection (e.g. "Reply"); may be the same as originator side, no default, used by spicy-protocol-analyzer
author: your name and email address, Benjamin Bannier <benjamin.bannier@corelight.com>, used by license
license: one of apache, bsd-2, bsd-3, mit, mpl-2, no default, used by license
versions: v0.99.0, v1.0.0, v2.0.0, v3.0.0, v3.0.1, v3.0.2
Protocol analyzers
For a TCP protocol analyzer the template generated the following declaration in
analyzer/*.evt:
protocol analyzer Foo over TCP:
parse originator with foo::Request,
parse responder with foo::Response;
Here we declare a Zeek protocol analyzer Foo which uses to different parsers
for the originator (client) and responder (server) side of the connection,
Request and Response. To use the same parser for both sides we would declare
parse with foo::Messages;
Message and connection semantics: UDP vs. TCP
The parsers have these stub implementations:
module foo;
public type Request = unit {
payload: bytes &eod;
};
public type Response = unit {
payload: bytes &eod;
};
We have used &eod to denote that we want to extract all data. The semantics
of all data differ between TCP and UDP parsers:
- UDP has no connection concept so Zeek synthesizes UDP "connections" from flows by
grouping UDP messages with the same
5-tuple
in a time window. UDP has no reassembly, so a new parser instance is
created for each UDP packet;
&eodmeans until the end of the current packet. - TCP: TCP supports connections and packet reassembly, so both sides of a
connection are modelled as streams with reassembled data;
&eodmeans until the end of the stream. The stream is unbounded.
For this reason one usually wants to model parsing of a TCP connection as a vector of protocol messages, e.g.,
public type Requests = unit {
: Request[];
};
type Request = unit {
# TODO: Parse protocol message.
};
- the length of the vector of messages is unspecified so it is detected dynamically
- to avoid storing an unbounded vector of messages we use an anonymous field for the vector
- parsing of the protocol messages is responsible for detecting when a message ends
Analyzer lifecycle
In Zeek's model all eligible analyzers would see the traffic.
- If analyzers detect traffic not matching their protocol, they should signal Zeek an analyzer violation so they stop receiving data. This is not an error during protocol detection.
- To signal matching traffic, analyzers should signal Zeek an analyzer confirmation. This e.g., leads to associating the protocol/service with the connection.
flowchart TD
N((fa:fa-cloud)) -->|data| Z(Zeek)
Z -->|looks up| Reg[Analyzers registered for port]
Z --> |forwards for matching| dpd[Analyzers with matching signatures]
Reg -->|data| A1
Reg --> |data|A2
dpd -->|data| B1
dpd --> |data|B2
dpd --> |data|B3
AC(fa:fa-bell analyzer_confirmation)
style AC fill:lightgreen
AV(fa:fa-bell analyzer_violation)
style AV fill:red
B1 -->|triggers| AV
B2 -->|triggers| AV
B3 -->|triggers| AC
A1 -->|triggers| AV
A2 -->|triggers| AV
To integrate the parser into this the template generated the following stub implementations in analyzer/zeek_*.spicy:
# TODO: Protocol analyzers should confirm once they are reasonably sure that
# they are indeed parsing the right protocol. Pick a unit that's a little bit
# into the parsing process here.
#
# on Foo::SUITABLE_UNIT::%done {
# zeek::confirm_protocol();
# }
# Any error bubbling up to the top unit will trigger a protocol rejection.
on Foo::Request::%error {
zeek::reject_protocol("error while parsing Foo request");
}
on Foo::Response::%error {
zeek::reject_protocol("error while parsing Foo reply");
}
We can use
zeek::confirm_protocol
and
zeek::reject_protocol
to signal Zeek.
Passing data to Zeek
Ultimately we want to make the parsed data available to Zeek for analysis and logging.
The handling of events is declared in the EVT file analyzer/*.EVT.
# TODO: Connect Spicy-side events with Zeek-side events. The example just
# defines simple example events that forwards the raw data (which in practice
# you don't want to do!).
on Foo::Request -> event Foo::request($conn, $is_orig, self.payload);
on Foo::Response -> event Foo::reply($conn, $is_orig, self.payload);
- the LHS specifies a Spicy hook in Spicy syntax
- the RHS specifies a (possibly generated) Zeek event in Zeek syntax
- we can reference Spicy data via
selfon the RHS - data for builtin Spicy types are converted automatically to equivalent Zeek types
- we can automatically generate Zeek record types from Spicy types
- information about the generated analyzer is accessible via magic
variables
$conn,$file,$packet,$is_orig
The event is handled on the Zeek side in scripts/main.zeek, e.g.,
# Example event defined in foo.evt.
event Foo::request(c: connection, is_orig: bool, payload: string)
{
hook set_session(c);
local info = c$foo;
info$request = payload;
}
Passing data to other Zeek analyzers (e.g., for analyzing subprotocols and files) is handled in a later section.
Forwarding to other analyzers
One often wants to forward an extracted payload to other analyzers.
- HTTP messages with files
- compressed files containing PE files
- protocols using other sub-protocols
Inside Spicy we can forward data from one parser to another one with sink
values,
but in a Zeek context we can also forward data to other analyzers (Spicy or
not).
Forwarding to file analyzers
Let's assume we are parsing protocol messages which contain bytes
corresponding to a file. We want to feed the file data into Zeek's file
analysis.
type Message = unit {
: bytes &chunked &size=512;
};
By using the &chunked attribute on the bytes its field hook is invoked soon as a chunk of data
arrives, even if the full data is not yet available.
The caveat is that only the final chunk will be stored once parsing is done. This is
fine since we usually do not store the data.
The protocol for passing data is:
- open a handle for a new Zeek file with
zeek::file_beginoptionally specifying a MIME type - pass information to Zeek, e.g., feed data or gaps, or notify Zeek about the expected size
- close the handle with
zeek::file_end
E.g.,
import zeek;
public type File = unit {
var h: string;
on %init { self.h = zeek::file_begin(); }
: bytes &chunked &eod {
zeek::file_data_in($$, self.h);
}
on %done { zeek::file_end(self.h); }
};
File handles need to be closed explicitly.
Not closing them would leak them for the duration of the connection.
Forwarding to protocol analyzers
Forwarding to protocol analyzers follows a similar protocol of opening a handle, interacting with it, and closing it.
For opening a handle, two APIs are supported:
function zeek::protocol_begin(analyzer: optional<string> = Null);
function zeek::protocol_handle_get_or_create(analyzer: string) : ProtocolHandle;
When using zeek::protocol_begin without argument all forwarded data will be
passed to Zeek's dynamic protocol detection (DPD).
Otherwise use the Zeek name of the analyzer, e.g.,
local h = zeek::protocol_handle_get_or_create("SSL");
You can inspect the output of zeek -NN for available analyzer names, e.g.,
$ zeek -NN | grep ANALYZER | grep SSL
[Analyzer] SSL (ANALYZER_SSL, enabled)
Sharing data across the same connection
We sometimes want to correlate information from the originator and responder side of a connection, and need to share data across the same connection.
Often we can do that in Zeek script land, e.g.,
# Example: Mapping of connections to their request method.
#
# NOTE: FOR DEMONSTRATION ONLY. WE MIGHT E.G., WANT TO ALLOW MULTIPLE REQUESTS
# PER CONNECTION.
global methods: table[conn_id] of string &create_expire=10sec;
event http_request(c: connection, method: string, original_URI: string, unescaped_URI: string, version: string)
{
# Store method for correlation.
methods[c$conn$id] = method;
}
event http_reply(c: connection, version: string, code: count, reason: string)
{
local id = c$conn$id;
if ( id in methods )
{
local method = methods[id];
print fmt("Saw reply %s to %s request on %s", code, method, id);
}
else
{
print fmt("Saw reply to unseen request on %s", id);
return;
}
}
This assumes that we always see requests before replies. Depending how we collect and process data this might not always hold.
If we need this information during parsing this is too late. Spicy allows
sharing information across both sides with unit
contexts.
When declaring a Spicy analyzer Zeek automatically sets up so originator and
responder of a connection share a context.
type Context = tuple<method: string>;
type Request = unit {
%context = Context;
method: /[^ \t\r\n]+/ { self.context().method = $$; }
# ...
};
type Reply = unit {
%context = Context;
# ...
on %done { print "Saw reply %s to %s request" % (code, self.context().method); }
};
Exercise
Starting from the default protocol analyzer template we want to (redundantly) pass the number of
bytes for Request to Zeek as well (i.e., the length of payload).
-
In the EVT file pass the number of
bytesin request'sself.payload.Solution
on Foo::Request -> event Foo::request($conn, $is_orig, self.payload, |self.payload|); -
Manually build your changed analyzer:
# Inside the directory of your generated analyzer (the directory with `zkg.meta`). mkdir build cd build/ cmake .. make -
Run the test suite. This runs tests against an included PCAP file. What do you see?
# Inside the directory of your generated analyzer (the directory with `zkg.meta`). cd testing/ btest -dvSolution
Test
tests.tracetest fails. Its sources are intesting/tests/trace.zeek... analyzer error in <..>/foo/analyzer/foo.evt, line 16: Event parameter mismatch, more parameters given than the 3 that the Zeek event expects -
Fix the signatures of the handlers for
Foo::requestso tests pass. What type do need to use on the Zeek side to pass the length (uint64in Spicy)?Hint
The type mappings are documented here.
Solution
In both
testing/tests/trace.zeekandscripts/main.zeekchange the signatures toevent Foo::request(c: connection, is_orig: bool, payload: string, len: count) {} -
Modify
testing/tests/trace.zeekto include the length in the baseline, i.e., change the test case forFoo::requesttoprint fmt("Testing Foo: [request] %s %s %d", c$id, payload, len);Rerun tests and update the test baseline with
# Inside the directory of your generated analyzer (the directory with `zkg.meta`). cd testing/ btest -uMake sure all tests pass with these changes.
Stage and commit all changes in the package repository.
git add -u git commit -v -m "Pass payload length to Zeek"Validate that the package also tests fine with
zkg.In contrast to the explicit invocations above,
zkgonly operates on files committed to the Git repository. It additionally requires that there are no uncommitted changes or untracked files in the repository.# Inside the directory of your generated analyzer (the directory with `zkg.meta`). # Make progress more verbose with `-vvv`. zkg -vvv test . -
Optional Also add the length to the Zeek log generated from the code in
scripts/main.zeek.Hint
This requires adding a
count &optional &logfield to theInforecord.Set the field from the event handler for
Foo::request.Update test baselines as needed.
Testing
Whether we like it or not, a Spicy analyzer is a piece of software. To make sure that it currently and it the future operates like intended we should strive to add tests to
- encode current behavior
- make sure our changes have the intended effects
- provide living documentation
When operating a Spicy analyzer as part of Zeek, work tends to fall into somewhat defined layers:
- parsing of raw bytes with one or more Spicy units
- interfacing with Zeek, e.g.,
- mapping of Spicy hooks to Zeek events in EVT files
- type mappings in EVT file
- hooks calling functions from the
zeekmodule (template-suggested fileanalyzer/zeek_ANALYZER.spicy)
- Zeek scripts consuming Spicy-generated events to create logs
Maintainable tests to cover a mix of
- single low-level pieces of functionality in isolation (unit tests),
- integration of different components (integration tests), and
- end-to-end tests to validate the full stack (system tests)
where lower levels tend to be more exhaustive.
Unit testing of individual parsers
Spicy comes with tools which given a Spicy grammar can read input from stdin or
file and forward to a parser (any public unit in the grammar):
spicy-dumpadditionally prints structured rendering of parsed unitsspicy-driverruns parser, outputs anyprintstatements- use
-fto read from file instead of stdin
Often spicy-dump is less intrusive since it requires not grammar changes.
Given a grammar
module foo;
public type X = unit {
a: uint8;
b: bytes &until=b"\x00";
};
To parse the input b"\x00foo\x00" to this parser we could feed it data with
Bash's printf builtin.
$ printf '\x01foo\x00' | spicy-dump -d foo.spicy
foo::X {
a: 1
b: foo
}
If using e.g., BTest we can snapshots this output to make sure it stays the same, e.g.,
# @TEST-EXEC: printf '\x01foo\x00' | spicy-dump -d foo.spicy >output-foo 2>&1
# @TEST-EXEC: btest-diff output-foo
The default BTest setup generated by the package template sets the environment
variable DIST to the root directory of the analyzer.
# ...
[environment]
DIST=%(testbase)s/..
# ...
Use this variable to access the original grammar in tests, e.g.,
# @TEST-EXEC: spicyc -d "${DIST}/analyzer/foo.spicy" -o foo.hlto
General tips
- often Spicy grammars compile faster in debug mode
-d, default to this in tests for faster turnaround - make sure to not accidentally append unintended newlines to input, e.g., use
echo -ninstead of plainecho - Bash's
printfbuiltin can be used to create binary data - select parser by passing
-p module::Unitif the grammar contains multiple entry points
Avoiding repeated analyzer recompilations
Since above spicy-dump invocation needs to compiles the full parser, consider compiling once to an HLTO file and reusing it for multiple checks in the same test, e.g.,
## Compile grammar.
# @TEST-EXEC: spicyc -d "${DIST}/analyzer/foo.spicy" -o foo.hlto
#
## Run tests.
# @TEST-EXEC: printf '\x01foo\x00' | spicy-dump -d foo.hlto >>output-foo 2>&1
# @TEST-EXEC: printf '\x02bar\x00' | spicy-dump -d foo.hlto >>output-foo 2>&1
Adding additional code for test
We might want to add additional code for testing only, e.g., add additional
logging, or check state with
assert
or assert-exception.
We can add testing-only module to the compilation during test, e.g.,
# @TEST-EXEC: spicyc -dj "${DIST}/analyzer/foo.spicy" %INPUT -o http.hlto
#
# @TEST-EXEC: printf '\x01foo\x00' | spicy-dump -d foo.hlto >>output-foo 2>&1
# @TEST-EXEC: printf '\x02bar\x00' | spicy-dump -d foo.hlto >>output-foo 2>&1
#
# @TEST-EXEC: btest-diff output
module test;
import foo;
on foo::Something { print self; }
Since one can implement hooks even for non-public units this is pretty powerful;
e.g., we can use this technique to observe data in anonymous fields,
module foo;
public type TcpMessages = unit {
: Message[]; # Anonymous field since list is unbounded.
};
type Message = unit {
# Consume and parse input ...
};
# In test code print individual message.
module test;
import foo;
on foo::Message { print self; }
Testing parsers with shared state
If parser share state, e.g., via a %context we might not be able to fully test them in isolation.
For this Spicy allows parsing batch input which are trace files similar to PCAPs.
As an example consider this PCAP:
$ tshark -r http-get.pcap
1 0.000000 ::1 → ::1 TCP 56150 → 8080 [SYN] Seq=0 Win=65535 Len=0 MSS=16324 WS=64 TSval=2906150528 TSecr=0 SACK_PERM
2 0.000147 ::1 → ::1 TCP 8080 → 56150 [SYN, ACK] Seq=0 Ack=1 Win=65535 Len=0 MSS=16324 WS=64 TSval=91891620 TSecr=2906150528 SACK_PERM
3 0.000173 ::1 → ::1 TCP 56150 → 8080 [ACK] Seq=1 Ack=1 Win=407744 Len=0 TSval=2906150528 TSecr=91891620
4 0.000185 ::1 → ::1 TCP [TCP Window Update] 8080 → 56150 [ACK] Seq=1 Ack=1 Win=407744 Len=0 TSval=91891620 TSecr=2906150528
5 0.000211 ::1 → ::1 HTTP GET /hello.txt HTTP/1.1
6 0.000233 ::1 → ::1 TCP 8080 → 56150 [ACK] Seq=1 Ack=87 Win=407680 Len=0 TSval=91891620 TSecr=2906150528
7 0.000520 ::1 → ::1 TCP HTTP/1.1 200 OK
8 0.000540 ::1 → ::1 TCP 56150 → 8080 [ACK] Seq=87 Ack=275 Win=407488 Len=0 TSval=2906150528 TSecr=91891620
9 0.000584 ::1 → ::1 HTTP HTTP/1.1 200 OK (text/plain)
10 0.000602 ::1 → ::1 TCP 56150 → 8080 [ACK] Seq=87 Ack=293 Win=407488 Len=0 TSval=2906150528 TSecr=91891620
11 0.000664 ::1 → ::1 TCP 56150 → 8080 [FIN, ACK] Seq=87 Ack=293 Win=407488 Len=0 TSval=2906150528 TSecr=91891620
12 0.000686 ::1 → ::1 TCP 8080 → 56150 [ACK] Seq=293 Ack=88 Win=407680 Len=0 TSval=91891620 TSecr=2906150528
13 0.000704 ::1 → ::1 TCP 8080 → 56150 [FIN, ACK] Seq=293 Ack=88 Win=407680 Len=0 TSval=91891620 TSecr=2906150528
14 0.000758 ::1 → ::1 TCP 56150 → 8080 [ACK] Seq=88 Ack=294 Win=407488 Len=0 TSval=2906150528 TSecr=91891620
We can convert this to a Spicy batch file batch.dat by loading a Zeek policy
script (redef Spicy::filename to change the output path):
$ zeek -Cr http-get.pcap -b policy/frameworks/spicy/record-spicy-batch
tracking [orig_h=::1, orig_p=56150/tcp, resp_h=::1, resp_p=8080/tcp, proto=6]
recorded 1 session total
output in batch.dat
Now batch.dat contains data for processing with e.g., spicy-driver and could be edited.
Most data portions in this batch file have lines terminated with CRLF, but only LF is rendered here.
!spicy-batch v2
@begin-conn ::1-56150-::1-8080-tcp stream ::1-56150-::1-8080-tcp-orig 8080/tcp%orig ::1-56150-::1-8080-tcp-resp 8080/tcp%resp
@data ::1-56150-::1-8080-tcp-orig 86
GET /hello.txt HTTP/1.1
Host: localhost:8080
User-Agent: curl/8.7.1
Accept: */*
@data ::1-56150-::1-8080-tcp-resp 274
HTTP/1.1 200 OK
content-length: 18
content-disposition: inline; filename="hello.txt"
last-modified: Thu, 23 Jan 2025 09:46:26 GMT
accept-ranges: bytes
content-type: text/plain; charset=utf-8
etag: "af67690:12:67920ff2:34f489e1"
date: Thu, 23 Jan 2025 09:46:41 GMT
@data ::1-56150-::1-8080-tcp-resp 18
Well hello there!
@end-conn ::1-56150-::1-8080-tcp
The originator and responder of this connection are on port 56150/tcp and
8080/tcp. Any analyzer with a either %port would be invoked for this
traffic automatically, e.g.,
module foo;
public type X = unit {
%port = 8080/tcp;
data: bytes &eod;
};
on foo::X::%done {
print self;
}
$ spicy-driver -F batch.dat parse.spicy -d
[$data=b"GET /hello.txt HTTP/1.1\x0d\x0aHost: localhost:8080\x0d\x0aUser-Agent: curl/8.7.1\x0d\x0aAccept: */*\x0d\x0a\x0d\x0a"]
[$data=b"HTTP/1.1 200 OK\x0d\x0acontent-length: 18\x0d\x0acontent-disposition: inline; filename=\"hello.txt\"\x0d\x0alast-modified: Thu, 23 Jan 2025 09:46:26 GMT\x0d\x0aaccept-ranges: bytes\x0d\x0acontent-type: text/plain; charset=utf-8\x0d\x0aetag: \"af67690:12:67920ff2:34f489e1\"\x0d\x0adate: Thu, 23 Jan 2025 09:46:41 GMT\x0d\x0a\x0d\x0aWell hello there!\x0a"]
The same mechanism works for mime types.
With >=spicy-1.13 (part of >=zeek-7.2) one can also externally specify how
analyzers should be mapped to ports so the grammars do not need to specify
%port/%mime-type, e.g.,
# Grammar has no `%port` attribute.
$ spicy-driver -F batch.dat parse.spicy -d --parser-alias '8080/tcp=foo::X'
Day-2 parser operation
Congratulations! You have finished development of a Spicy-based Zeek analyzer which produces Zeek logs when exposed to its intended input; you even added a test suite to ensure that it behaves as intended.
Your analyzer works in a controlled lab environment, but deploying and continuously operating it in a production environment will introduce new challenges, e.g.,
- Your parser will see traffic you had not anticipated.
- The traffic mix in production might force you to reevaluate tradeoffs you made during development.
Concerns like this are often summarized as Day-2 problems in contrast to design and planning (Day-0) and deploying a working prototype (Day-1).
This chapter will discuss some tools and approaches to address them. We will look at this under the assumption that PCAPs have been captured. Another import concern in production is monitoring which we will not discuss in here.
Debugging
We need to debug runtime behavior of parsers both during development as well as in production. This chapter gives an overview of the available tools.
In following we use a Zeek protocol analyzer for the
TFTP protocol
zeek/spicy-tftp as test environment.
To have access to its sources let's install it from a local clone.
Create and switch to a local clone of the parser at version v0.0.5:
git clone https://github.com/zeek/spicy-tftp -b v0.0.5
cd spicy-tftp/
Briefly familiarize yourself with the parser.
-
Looking at its EVT file
analyzer/tftp.evt, what traffic does the analyzer trigger on?Solution
This is an analyzer for UDP traffic. It is triggered for UDP traffic on port 69.protocol analyzer spicy::TFTP over UDP: parse with TFTP::Packet, port 69/udp; -
Does this analyzer perform dynamic protocol detection (DPD)?
Solution
No, no DPD signatures are loaded (
@load-sig) in any of its Zeek scripts in e.g.,scripts/. -
When in the connection lifecycle does this analyzer invoke
spicy::accept_input()(orzeek::confirm_inputfor older versions)?Solution
For each received message in
Requestinanalyzer/tftp.spicy:type Request = unit(is_read: bool) { # ... on %done { spicy::accept_input(); } }; -
How does this analyzer behave on parse errors?
Solution
The analyzer does not seem to perform resynchronization (no
&synchronizeanywhere in its sources). It should report an analyzer violation on parse errors. -
Which Zeek events does the Spicy parser raise?
Solution
on TFTP::Request if ( is_read ) -> event tftp::read_request($conn, $is_orig, self.filename, self.mode); on TFTP::Request if ( ! is_read ) -> event tftp::write_request($conn, $is_orig, self.filename, self.mode); on TFTP::Data -> event tftp::data($conn, $is_orig, self.num, self.data); on TFTP::Acknowledgement -> event tftp::ack($conn, $is_orig, self.num); on TFTP::Error -> event tftp::error($conn, $is_orig, self.code, self.msg); -
Which logs does the analyzer provide? What are its content? Try to look at only the sources and ignore files under
testingfor this.Solution
Grepping the analyzer sources for
create_streamindicates that it produces a logtftp.log.Log::create_stream(TFTP::LOG, [$columns = Info, $ev = log_tftp, $path="tftp"]);The columns of the log are the fields of
TFTP::Infomarked&log.
Further reading
Logging basic parser operation
Let's install the analyzer (assuming we are in local clone of
zeek/spicy-tftp at v0.0.5).
$ zkg install .
The following packages will be INSTALLED:
/root/spicy-tftp (main)
Proceed? [Y/n]
Running unit tests for "/root/spicy-tftp"
Installing "/root/spicy-tftp".....
Installed "/root/spicy-tftp" (main)
Loaded "/root/spicy-tftp"
If we replay a a PCAP with TFTP traffic we see no connections marked with
service tftp in conn.log, or a tftp.log:
$ zeek -r testing/Traces/tftp_rrq.pcap
$ cat conn.log | zeek-cut -C ts id.orig_h id.orig_p id.resp_h id.resp_p service
#separator \x09
#set_separator ,
#empty_field (empty)
#unset_field -
#path conn
#open 2025-01-17-11-18-34
#fields ts id.orig_h id.orig_p id.resp_h id.resp_p service
#types time addr port addr port string
1367411052.077243 192.168.0.10 3445 192.168.0.253 50618 -
1367411051.972852 192.168.0.253 50618 192.168.0.10 69 -
#close 2025-01-17-11-18-34
Both Zeek's Spicy plugin as well as Spicy parsers can emit additional debug
information at runtime. The value of the environment variable HILTI_DEBUG
controls this behavior which can take e.g., the following values:
HILTI_DEBUG=zeek: information about Zeek's Spicy plugin
Available if parser was built in debug mode:
HILTI_DEBUG=spicy: high-level information about Spicy parser behaviorHILTI_DEBUG=spicy-verbose: low-level information about Spicy parser behavior
Multiple values can be separated by :, e.g, HILTI_DEBUG=zeek:spicy.
Zeek comes with its own debug streams which are enabled if Zeek was compiled with --enable-debug:
$ zeek -B help
Enable debug output into debug.log with -B <streams>.
<streams> is a case-insensitive, comma-separated list of streams to enable:
broker
cluster
dpd
file-analysis
hashkey
input
logging
main-loop
notifiers
packet-analysis
pktio
plugins
rules
scripts
serial
spicy
string
supervisor
threading
tm
zeekygen
Every plugin (see -N) also has its own debug stream:
plugin-<plugin-name> (replace '::' in name with '-'; e.g., '-B plugin-Zeek-JavaScript')
Pseudo streams:
verbose Increase verbosity.
all Enable all streams at maximum verbosity.
To debug Spicy analyzers the most useful streams are dpd, file-analysis, and spicy.
With HILTI_DEBUG=zeek we can see why no logs are produced:
$ HILTI_DEBUG=zeek zeek -r testing/Traces/tftp_rrq.pcap
[zeek] Registering TCP protocol analyzer Finger with Zeek
[zeek] Registering TCP protocol analyzer LDAP_TCP with Zeek
[zeek] Registering UDP protocol analyzer LDAP_UDP with Zeek
[zeek] Registering TCP protocol analyzer PostgreSQL with Zeek
[zeek] Registering UDP protocol analyzer QUIC with Zeek
[zeek] Registering UDP protocol analyzer Syslog with Zeek
[zeek] Registering TCP protocol analyzer spicy::WebSocket with Zeek
[zeek] Done with post-script initialization
[zeek] Shutting down Spicy runtime
The TFTP analyzer does not seem to register with Zeek even though it is installed 🤨.
Cause in this case: local.zeek does not load zkg-installed plugins.
# Uncomment this to source zkg's package state
# @load packages
If we uncomment that line or manually load packages we produce output.
$ HILTI_DEBUG=zeek zeek -r testing/Traces/tftp_rrq.pcap -C packages
[zeek] Registering TCP protocol analyzer Finger with Zeek
[zeek] Registering TCP protocol analyzer LDAP_TCP with Zeek
[zeek] Registering UDP protocol analyzer LDAP_UDP with Zeek
[zeek] Registering TCP protocol analyzer PostgreSQL with Zeek
[zeek] Registering UDP protocol analyzer QUIC with Zeek
[zeek] Registering UDP protocol analyzer Syslog with Zeek
[zeek] Registering TCP protocol analyzer spicy::WebSocket with Zeek
[zeek] Registering UDP protocol analyzer spicy::TFTP with Zeek <---- HERE
[zeek] Scheduling analyzer for port 69/udp
[zeek] Done with post-script initialization
[zeek] confirming protocol 110/0 <---- HERE
[zeek] Shutting down Spicy runtime
$ cat tftp.log
#separator \x09
#set_separator ,
#empty_field (empty)
#unset_field -
#path tftp
#open 2025-01-17-12-18-09
#fields ts uid id.orig_h id.orig_p id.resp_h id.resp_p wrq fname mode uid_data size block_sent block_acked error_code error_msg
#types time string addr port addr port bool string string string count count count count string
1367411051.972852 Clw8cG1TykDCJQXei2 192.168.0.253 50618 192.168.0.10 69 F rfc1350.txt octet CNR2ur1rbdum6auCFi 24599 49 49 - -
#close 2025-01-17-12-18-09
Building Spicy parsers with debug support
Debug support for Spicy parsers needs to be compiled in.
One option: Change analyzer CMake configuration in zkg.meta's build_command:
- build_command = ... cmake .. && cmake --build .
+ build_command = ... cmake .. -DCMAKE_BUILD_TYPE=Debug && cmake --build .
Commit changes and install patched analyzer:
$ git add -u && git commit -m'Switch to debug mode'
[main e2826a1] Switch to debug mode
1 file changed, 1 insertion(+), 1 deletion(-)
$ zkg install .
Instead of installing one could also just use such a debug install for local debugging, e.g., from tests. In that case one invokes CMake directly and could use the following invocation:
# Inside build directory.
$ cmake -DCMAKE_BUILD_TYPE=Debug ..
Exercise
-
What kind of output is emitted with
HILTI_DEBUG=spicy? Can you relate it to the Spicy grammar inanalyzer/tftp.spicy? -
What additional output is emitted with
HILTI_DEBUG=spicy:spicy-verbose?
Exercise: Input not matching parser grammar
This exercises stopped working with zeek-8.0.0 due to changes to how Zeek logs
analyzer
failures,
but going trying this exercise with the zeek/zeek:7.2 container image should
still be instructive. Updating this exercise to newer Zeek versions is tracked
in #36.
The PCAP tftp-unsupported.pcap contains TFTP
traffic, but there are problems. Using just the logs produced by Zeek figure
out what is the issue.
-
Make sure you have the package
zeek/spicy-tftpin versionv0.0.5installed, its analyzerspicy_TFTPis working, and the package scripts are loaded.Hint
The package should be listed
zkg, e.g.,$ zkg list zeek/zeek/spicy-tftp (installed: v0.0.5) - Spicy-based analyzer for the TFTP protocol.Otherwise install it with
$ zkg install zeek/spicy-tftp --version v0.0.5 The following packages will be INSTALLED: zeek/zeek/spicy-tftp (v0.0.5) Proceed? [Y/n] Running unit tests for "zeek/zeek/spicy-tftp" Installing "zeek/zeek/spicy-tftp". Installed "zeek/zeek/spicy-tftp" (v0.0.5) Loaded "zeek/zeek/spicy-tftp"If the package is installed a TFTP analyzer should be listed by
zeek -NN, e.g.,$ zeek -NN | grep -i tftp [Analyzer] spicy_TFTP (ANALYZER_SPICY_TFTP, enabled)Running the analyzer on some test data should produce a
tftp.log. For this the scripts from the package need to be loaded, e.g.,@load packagesshould be present inlocal.zeek.Using the file
tftp_rrq.pcapfrom the test data in the package repository:$ zeek -Cr tftp_rrq.pcap $ ls *.log conn.log packet_filter.log tftp.log $ cat tftp.log | jq { "ts": 1737142107.374696, "uid": "CAMTBX2d54B930rgkg", "id.orig_h": "127.0.0.1", "id.orig_p": 60027, "id.resp_h": "127.0.0.1", "id.resp_p": 69, "wrq": false, "fname": "hello.txt", "mode": "octet", "uid_data": "Csmqzc1PPz5ZPJ1uj", "size": 0, "block_sent": 0, "block_acked": 0 } -
Run
zeekontftp-unsupported.pcap. This should produce at least the log filesconn.log,tftp.logandanalyzer.log.Hint
If you only see
packet_filter.logandweird.logyou need to invokezeekwith an additional argument.Hint
weird.logreports that the PCAP has bad checksums.cat weird.log | jq { "ts": 1737142107.374696, "id.orig_h": "127.0.0.1", "id.orig_p": 0, "id.resp_h": "127.0.0.1", "id.resp_p": 0, "name": "bad_IP_checksum", "notice": false, "peer": "zeek", "source": "IP" }Run
zeekwith-C(or--no-checksums) causes Zeek to ignore checksums and produce the three log files. -
Working top to bottom, what is going on and what is the issue?
a. What do you see in
conn.log?Solution
- two connections are reported,
spicy_tftp_datawith data payload, andspicy_tftpfor some request with TCP data not ack'd (leading to the checksum error) - the
resp_handresp_pofspicy_tftp_dataconnection match theorig_handorig_pof thespicy_tftpconnection, so they seem to belong to the same TFTP transaction - both connections report some data
- apart from the missing ACK nothing seems obviously off
$ cat conn.log | jq { "ts": 1737142107.374971, "uid": "Csmqzc1PPz5ZPJ1uj", "id.orig_h": "127.0.0.1", "id.orig_p": 50012, "id.resp_h": "127.0.0.1", "id.resp_p": 60027, "proto": "udp", "service": "spicy_tftp_data", "duration": 0.0007979869842529297, "orig_bytes": 468, "resp_bytes": 12, "conn_state": "SF", "local_orig": true, "local_resp": true, "missed_bytes": 0, "history": "Dd", "orig_pkts": 3, "orig_ip_bytes": 552, "resp_pkts": 3, "resp_ip_bytes": 96, "ip_proto": 17 } { "ts": 1737142107.374696, "uid": "CAMTBX2d54B930rgkg", "id.orig_h": "127.0.0.1", "id.orig_p": 60027, "id.resp_h": "127.0.0.1", "id.resp_p": 69, "proto": "udp", "service": "spicy_tftp", "conn_state": "S0", "local_orig": true, "local_resp": true, "missed_bytes": 0, "history": "D", "orig_pkts": 1, "orig_ip_bytes": 58, "resp_pkts": 0, "resp_ip_bytes": 0, "ip_proto": 17 }b. What do you see in
tftp.log?Solution
- a single TFTP transaction for reading the file
hello.txtis reported - both
block_sentandblock_ackedare reported as zero, but no error seems to have occurred
$ cat tftp.log | jq { "ts": 1737142107.374696, "uid": "CAMTBX2d54B930rgkg", "id.orig_h": "127.0.0.1", "id.orig_p": 60027, "id.resp_h": "127.0.0.1", "id.resp_p": 69, "wrq": false, "fname": "hello.txt", "mode": "octet", "uid_data": "Csmqzc1PPz5ZPJ1uj", "size": 0, "block_sent": 0, "block_acked": 0 }b. What do you see in
analyzer.log? How it related to the grammar?Solution
- the TFTP analyzer
SPICY_TFTPreports a protocol violation since it sees an unknown and unhandled opcode (Opcode::<unknown-6>) - the payload data triggering this error is
b"\x00\x06blksize\x00256\x00"
$ cat analyzer.log | jq { "ts": 1737142107.374971, "cause": "violation", "analyzer_kind": "protocol", "analyzer_name": "SPICY_TFTP", "uid": "Csmqzc1PPz5ZPJ1uj", "id.orig_h": "127.0.0.1", "id.orig_p": 50012, "id.resp_h": "127.0.0.1", "id.resp_p": 60027, "failure_reason": "no matching case in switch statement for value 'Opcode::<unknown-6>' (/root/spicy-tftp/analyzer/tftp.spicy:20:5-26:10)", "failure_data": "\\x00\\x06blksize\\x00256\\x00" }Looking at the error location
/root/spicy-tftp/analyzer/tftp.spicy:20:5-26:10, the protocol violation happens since noOpcode=6is modelled in the grammar.public type Packet = unit { # public top-level entry point for parsing op: uint16 &convert=Opcode($$); switch ( self.op ) { # ~~~~~~~~~~~~~~~~~~~~ no matching case in switch statement for value 'Opcode::<unknown-6>' Opcode::RRQ -> rrq: Request(True); Opcode::WRQ -> wrq: Request(False); Opcode::DATA -> data: Data; Opcode::ACK -> ack: Acknowledgement; Opcode::ERROR -> error: Error; }; };# TFTP supports five types of packets [...]: # # opcode operation # 1 Read request (RRQ) # 2 Write request (WRQ) # 3 Data (DATA) # 4 Acknowledgment (ACK) # 5 Error (ERROR) type Opcode = enum { RRQ = 0x01, WRQ = 0x02, DATA = 0x03, ACK = 0x04, ERROR = 0x05 }; - two connections are reported,
-
Figure out the spec of what you need to implement to parse this connection.
Hint
Possible search terms:
TFTP opcode 6 RFC blksize(🔎 duckduckgo.com)Solution
Relevant RFCs:
RFC2348 is specifically about the
blksizenegotiation we are seeing here, but implementing option support more generally according to RFC2347 does not seem much more work. -
Write a minimal extension to the grammar so it can parse this connection (ignore logging for now).
You only need to extend parsing for the response, why is the extra data in the request ignored? Add parsing to the request side as well and make sure we do not miss additional data in the future.
Sometimes surrounding context is needed in addition to the payload information from the logs, but probably not here. If you still want to have a look at the PCAP with Wireshark you could install and run
tsharklike this:$ apt-get update $ apt-get install -y tshark $ tshark -r /workspaces/zeek-playground/tftp-unsupported.pcap Running as user "root" and group "root". This could be dangerous. 1 0.000000 127.0.0.1 → 127.0.0.1 TFTP 62 Read Request, File: hello.txt, Transfer type: octet, blksize=256 2 0.000275 127.0.0.1 → 127.0.0.1 TFTP 46 Option Acknowledgement, blksize=256 3 0.000520 127.0.0.1 → 127.0.0.1 TFTP 36 Acknowledgement, Block: 0 4 0.000590 127.0.0.1 → 127.0.0.1 TFTP 292 Data Packet, Block: 1 5 0.000816 127.0.0.1 → 127.0.0.1 TFTP 36 Acknowledgement, Block: 1 6 0.000876 127.0.0.1 → 127.0.0.1 TFTP 226 Data Packet, Block: 2 (last) 7 0.001073 127.0.0.1 → 127.0.0.1 TFTP 36 Acknowledgement, Block: 2Solution
-
To parse this trace without errors we only need to add support for Option Acknowledgment (OACK) packets.
-
Add support for OACK
Opcode:type Opcode = enum { RRQ = 0x01, WRQ = 0x02, DATA = 0x03, ACK = 0x04, - ERROR = 0x05 + ERROR = 0x05, + OACK = 0x06, }; -
Add support for parsing OACK packets ignoring data for now since it will not be logged:
public type Packet = unit { # public top-level entry point for parsing op: uint16 &convert=Opcode($$); switch ( self.op ) { Opcode::RRQ -> rrq: Request(True); Opcode::WRQ -> wrq: Request(False); Opcode::DATA -> data: Data; Opcode::ACK -> ack: Acknowledgement; Opcode::ERROR -> error: Error; + Opcode::OACK -> : skip bytes &eod; # Ignore OACK payload for now. }; };
-
-
Making sure all request data is consumed.
The request was parsed successfully even with the additional option data since the parser operates on UDP data. For UDP data "connections" are only assembled by Zeek, but on the Spicy side each packet is parsed individually, so there is no stray data "left on the wire" for any other parser to stumble over.
With that any extra data passed to
Requestsimply falls off the end. We could encode that no additional data is expected by adding askipfield which consumesbytesuntil&eod, but can at most consume zero bytes (i.e., nothing expected until EOD).type Request = unit(is_read: bool) { filename: bytes &until=b"\x00"; mode: bytes &until=b"\x00"; + : skip bytes &eod &max-size=0; on %done { spicy::accept_input(); } }; -
Consume options on the request side.
By consuming an unknown number of options we activate lookahead parsing which would fail for non-option data, so above explicit skipping is not needed anymore.
-
Add a unit to parse options:
+type Option = unit { + name: skip bytes &until=b"\x00"; + value: skip bytes &until=b"\x00"; +}; -
Extend request to also consume options (data ignored for now):
type Request = unit(is_read: bool) { filename: bytes &until=b"\x00"; mode: bytes &until=b"\x00"; + options: skip Option[]; on %done { spicy::accept_input(); } };
-
-
-
If you have not already done so, add testing for your parser changes. What are the possible approaches and where should we test?
Solution
Applying the terminology described in the section about testing:
- parsing changes affect individual units
- the changed units are
public - changes only affect the Spicy parsing layer with no visible external effects beyond absence of parse errors
Ideally add some test based on a Spicy batch file, but for TFTP we make the connection between request and response only in the Zeek scripts. Instead add an system, end-to-end test based on the original PCAP (which is small):
# @TEST-EXEC: zeek -NN Zeek::Spicy > l # # @TEST-EXEC: zeek -Cr ${TRACES}/tftp_blksize_option.pcap ${PACKAGE} # # Note: Try to extract relevant columns from common logs to # reduce churn with upstream changes. # @TEST-EXEC: cat conn.log | zeek-cut uid service orig_pkts resp_pkts > conn.log.min # @TEST-EXEC: btest-diff conn.log.min # # @TEST-EXEC: btest-diff tftp.logAdd some unit-style tests:
## Precompile grammar so we can reuse it across multiple tests. # @TEST-EXEC: spicyc -dj ${DIST}/analyzer/tftp.spicy %INPUT -o tftp.hlto ## Note: We use bash's `printf` to output binary data (BTest defaults to `sh`) ## below. We should capture this in a script for reuse. ## Validate parsing of OACK responses ## ---------------------------------- ## ## Baseline: ## ## TFTP::Packet { ## op: OACK ## } ## # @TEST-EXEC: bash -c 'printf "\x00\x06blksize\x00256\x00"' | spicy-dump tftp.hlto >oack.log 2>&1 # @TEST-EXEC: btest-diff oack.log ## Validate parsing of options in requests ## --------------------------------------- ## No options ## ~~~~~~~~~~ ## ## Baseline: ## ## TFTP::Packet { ## op: RRQ ## rrq: TFTP::Request { ## filename: hello.txt ## mode: octet ## options: [] ## } ## } ## # @TEST-EXEC: bash -c 'printf "\x00\x01hello.txt\x00octet\x00"' | spicy-dump tftp.hlto >request-no-opts.log 2>&1 # @TEST-EXEC: btest-diff request-no-opts.log ## Single option ## ~~~~~~~~~~~~~ ## ## Baseline: ## ## TFTP::Packet { ## op: RRQ ## rrq: TFTP::Request { ## filename: hello.txt ## mode: octet ## options: [ ## TFTP::Option {} ## ] ## } ## } ## # @TEST-EXEC: bash -c 'printf "\x00\x01hello.txt\x00octet\x00blksize\x00256\x00"' | spicy-dump tftp.hlto >request-single-opt.log 2>&1 # @TEST-EXEC: btest-diff request-single-opt.log ## Multiple options ## ~~~~~~~~~~~~~~~~ ## ## Deliberately test an unsupported option with slightly weird value (empty). ## ## Baseline: ## ## TFTP::Packet { ## op: RRQ ## rrq: TFTP::Request { ## filename: hello.txt ## mode: octet ## options: [ ## TFTP::Option {} ## TFTP::Option {} ## ] ## } ## } ## # @TEST-EXEC: bash -c 'printf "\x00\x01hello.txt\x00octet\x00blksize\x00256\x00my special option\x00\x00"' | spicy-dump tftp.hlto >request-two-opts.log 2>&1 # @TEST-EXEC: btest-diff request-two-opts.log
Spoiler
During this exercise you basically implemented a solution for zeek/spicy-tftp#14.
Key takeaways
analyzer.logis needed to operate parsers and should be ingested into the SIEM solution- similarly,
dpd.logcontains useful information about the DPD phase and is needed to diagnose issues where parsers never make it past DPD
- similarly,
- even if a parser fully supports a protocols RFC, extensions are common (codified in another RFC, or private)
- Always try to add tests when changing an analyzer. This not only makes sure that you do not accidentally break your parser, but also serves as living documentation of its features.
Profiling
Profiling is the process of measuring where computing resources (typically: CPU time, memory) are spent in a program at runtime.
With profiling information we can validate that our program stays within its resource budget, or quantitatively compare the runtime characteristics of different implementations.
Effective use of profiling often involves a mix of profiling during development as well as in production (likely: at different granularity). To prevent regressions it needs to be continuous.
Spicy supports both instrumentation to emit high-level profiling information as well as low-level profiling with typical tools. In the following we discuss these approaches separately.
High-level profiling with instrumentation
Spicy allows to instrument generated with profiling information with small performance impact.
Emitting profiling information is activated by invoking the tool performing the
compilation (e.g., spicyc or spicyz) with -Z.
If the code is part of a Zeek package with CMake setup one can pass additional
spicyz flags via the CMake variable SPICYZ_FLAGS, e.g.,
$ cmake -DSPICYZ_FLAGS='-Z' ..
If needed this can also be patched into the build_command in zkg.meta.
Information is collected on a per-function basis and includes:
- total number of invocations
- elapsed time
- fraction of elapsed time spent in this function
- per top-level parser invocation
- in total
- volume of input data consumed function (for parsers)
If parsing with Spicy-only tools (e.g., spicy-driver)
profiling information is emitted to stderr on exit.
When running with zeek one needs to set Spicy::enable_profiling=T to emit
profiling output on exit.
Tangent: Implementation of parser runtime behavior
Spicy parsers consist of one or more units with fields which are parsers as
well. Overall code concentrates on describing some "shape" of the data, but
additional procedural code can be attached during a parser's lifetime.
The Spicy compiler lowers this code to an intermediary language (HILTI) which in turn gets emitted as C++ code:
- Units are modelled as C++ classes (matching name), with top-level parsing
entry points
parse1/parse2/parse3(member functions of the class for the unit). - additional internal helper methods
__parse...are invoked during parsing - hooks are invoked from matching
__on_0x25_...dispatcher functions - all this code interacts with types and functions in Spicy's and HILTI's runtime libraries
Example: spicy-http
We are spicy-http as example parser.
git clone https://github.com/zeek/spicy-http
cd spicy-http/
Invoke the top-level parser Requests which parses a list Request[]. We see
that the bulk of the work happens in the parsing of Request itself.
$ printf 'GET / HTTP/1.1\r\n\r\n' | \
spicy-driver -Z analyzer/analyzer.spicy -p HTTP::Requests
#
# Profiling results
#
#name count time avg-% total-% volume
hilti/func/HTTP::Message::__on_0x25_init 1 167 0.07 0.07 -
hilti/func/HTTP::Message::__on_end_of_hdr 1 166 0.07 0.07 -
hilti/func/HTTP::Message::__parse_HTTP__Message_5_stage2 1 3292 1.34 1.34 -
hilti/func/HTTP::Message::__parse_headers_5_stage1 1 1542 0.63 0.63 -
hilti/func/HTTP::Message::__parse_stage1 1 13541 5.52 5.52 -
hilti/func/HTTP::Request::__parse_HTTP__Request_2_stage2 1 58125 23.71 23.71 -
hilti/func/HTTP::Request::__parse_stage1 1 67959 27.72 27.72 -
hilti/func/HTTP::RequestLine::__parse_HTTP__RequestLine_3_stage2 1 33542 13.68 13.68 -
hilti/func/HTTP::RequestLine::__parse_stage1 1 34125 13.92 13.92 -
hilti/func/HTTP::Requests::__parse_HTTP__Requests_stage2 1 83166 33.92 33.92 -
hilti/func/HTTP::Requests::__parse__anon_2_stage1 1 82625 33.70 33.70 -
hilti/func/HTTP::Requests::__parse_stage1 1 93000 37.93 37.93 -
hilti/func/HTTP::Requests::parse3 1 102917 41.98 41.98 -
hilti/func/HTTP::Version::__parse_HTTP__Version_5_stage2 1 16708 6.81 6.81 -
hilti/func/HTTP::Version::__parse_stage1 1 17250 7.04 7.04 -
hilti/func/HTTP::__register_HTTP_Body 1 38958 15.89 15.89 -
hilti/func/HTTP::__register_HTTP_Chunk 1 250 0.10 0.10 -
hilti/func/HTTP::__register_HTTP_Chunks 1 125 0.05 0.05 -
hilti/func/HTTP::__register_HTTP_Content 1 458 0.19 0.19 -
hilti/func/HTTP::__register_HTTP_Header 1 166 0.07 0.07 -
hilti/func/HTTP::__register_HTTP_Message 1 42 0.02 0.02 -
hilti/func/HTTP::__register_HTTP_Replies 1 10875 4.44 4.44 -
hilti/func/HTTP::__register_HTTP_Reply 1 250 0.10 0.10 -
hilti/func/HTTP::__register_HTTP_ReplyLine 1 83 0.03 0.03 -
hilti/func/HTTP::__register_HTTP_Request 1 83 0.03 0.03 -
hilti/func/HTTP::__register_HTTP_RequestLine 1 209 0.09 0.09 -
hilti/func/HTTP::__register_HTTP_Requests 1 458 0.19 0.19 -
hilti/func/HTTP::__register_HTTP_Version 1 83 0.03 0.03 -
hilti/func/filter::__register_filter_Base64Decode 1 416 0.17 0.17 -
hilti/func/filter::__register_filter_Zlib 1 291 0.12 0.12 -
hilti/total 1 245167 100.00 100.00 -
spicy/prepare/input/HTTP::Requests 1 1875 0.76 0.76 -
spicy/unit/HTTP::Message 1 13292 5.42 5.42 2
spicy/unit/HTTP::Message::body 1 125 0.05 0.05 0
spicy/unit/HTTP::Message::end_of_hdr 1 500 0.20 0.20 2
spicy/unit/HTTP::Message::headers 1 2291 0.93 0.93 0
spicy/unit/HTTP::Request 1 67709 27.62 27.62 18
spicy/unit/HTTP::Request::message 1 23292 9.50 9.50 2
spicy/unit/HTTP::Request::request 1 34541 14.09 14.09 16
spicy/unit/HTTP::RequestLine 1 33875 13.82 13.82 16
spicy/unit/HTTP::RequestLine::_anon_6 1 2208 0.90 0.90 1
spicy/unit/HTTP::RequestLine::_anon_7 1 500 0.20 0.20 1
spicy/unit/HTTP::RequestLine::_anon_8 1 1375 0.56 0.56 2
spicy/unit/HTTP::RequestLine::method 1 9875 4.03 4.03 3
spicy/unit/HTTP::RequestLine::uri 1 1209 0.49 0.49 1
spicy/unit/HTTP::RequestLine::version 1 17583 7.17 7.17 8
spicy/unit/HTTP::Requests 1 92792 37.85 37.85 18
spicy/unit/HTTP::Requests::_anon_2 1 82917 33.82 33.82 18
spicy/unit/HTTP::Requests::_anon_2::_anon 1 68583 27.97 27.97 18
spicy/unit/HTTP::Version 1 17000 6.93 6.93 8
spicy/unit/HTTP::Version::_anon_5 1 13708 5.59 5.59 5
spicy/unit/HTTP::Version::number 1 2583 1.05 1.05 3
When running as part of Zeek additional code is executing, we e.g., see the
work from forwarding message bodies into Zeek file analysis framework via
file_data_in:
$ cmake -B build -DSPICYZ_FLAGS='-Z'
$ make -C build/
$ zeek -Cr tests/traces/http-non-default-port.pcap \
build/http.hlto analyzer \
'Spicy::enable_profiling=T'
#
# Profiling results
#
#name count time avg-% total-% volume
hilti/func/HTTP::Body::__on_0x25_done 1 250 0.00 0.00 -
hilti/func/HTTP::Body::__on_0x25_init 1 27750 0.10 0.10 -
hilti/func/HTTP::Body::__parse_HTTP__Body_6_stage2 1 1439417 5.12 5.12 -
...
spicy/unit/HTTP::Version::_anon_5 2 4832 0.01 0.02 10
spicy/unit/HTTP::Version::number 2 3583 0.01 0.01 6
zeek/event/http_all_headers 2 250 0.00 0.00 -
zeek/event/http_begin_entity 2 1750 0.00 0.01 -
zeek/event/http_content_type 2 292 0.00 0.00 -
zeek/event/http_end_entity 2 1542 0.00 0.01 -
zeek/event/http_entity_data 1 2500 0.01 0.01 -
zeek/event/http_header 9 10960 0.00 0.04 -
zeek/event/http_message_done 2 2917 0.01 0.01 -
zeek/event/http_reply 1 2042 0.01 0.01 -
zeek/event/http_request 1 4500 0.02 0.02 -
zeek/rt/confirm_protocol 1 3875 0.01 0.01 -
zeek/rt/current_conn 17 2540 0.00 0.01 -
zeek/rt/current_is_orig 15 790 0.00 0.00 -
zeek/rt/event_arg_type 36 4832 0.00 0.02 -
zeek/rt/file-stack-push 1 32625 0.12 0.12 -
zeek/rt/file-stack-remove 1 167 0.00 0.00 -
zeek/rt/file_begin 1 76125 0.27 0.27 -
zeek/rt/file_data_in 1 1060042 3.77 3.77 -
zeek/rt/file_end 1 708 0.00 0.00 -
zeek/rt/file_set_size 1 2167 0.01 0.01 -
zeek/rt/file_state 4 708 0.00 0.00 -
zeek/rt/file_state_stack 6 374 0.00 0.00 -
zeek/rt/internal_handler 49 10334 0.00 0.04 -
zeek/rt/raise_event 17 2832 0.00 0.01 -
Low-level profiling with standard system tools
Since Spicy just emits C++ code one can use standard system tools like e.g.,
perf to collect profiling information.
In its default configuration spicyc/spicyz build in the mode they were
themself compiled in. For upstream packages this means unstripped release
binaries which expose names of called functions, but not per-line information
for e.g., perf annotate.
zeek -Cr tests/traces/http-non-default-port.pcap build/http.hlto analyzer
Example flamegraphs displayed with
samply zooming in on just code running
as part of Spicy parsers (<1% of total elapsed time):
Spicy parsers run on a fiber abstraction which can confuse tools like perf annotate which attempt to restore stack traces. The code to look for is
anything running below a hilti::rt::detail::Callback.
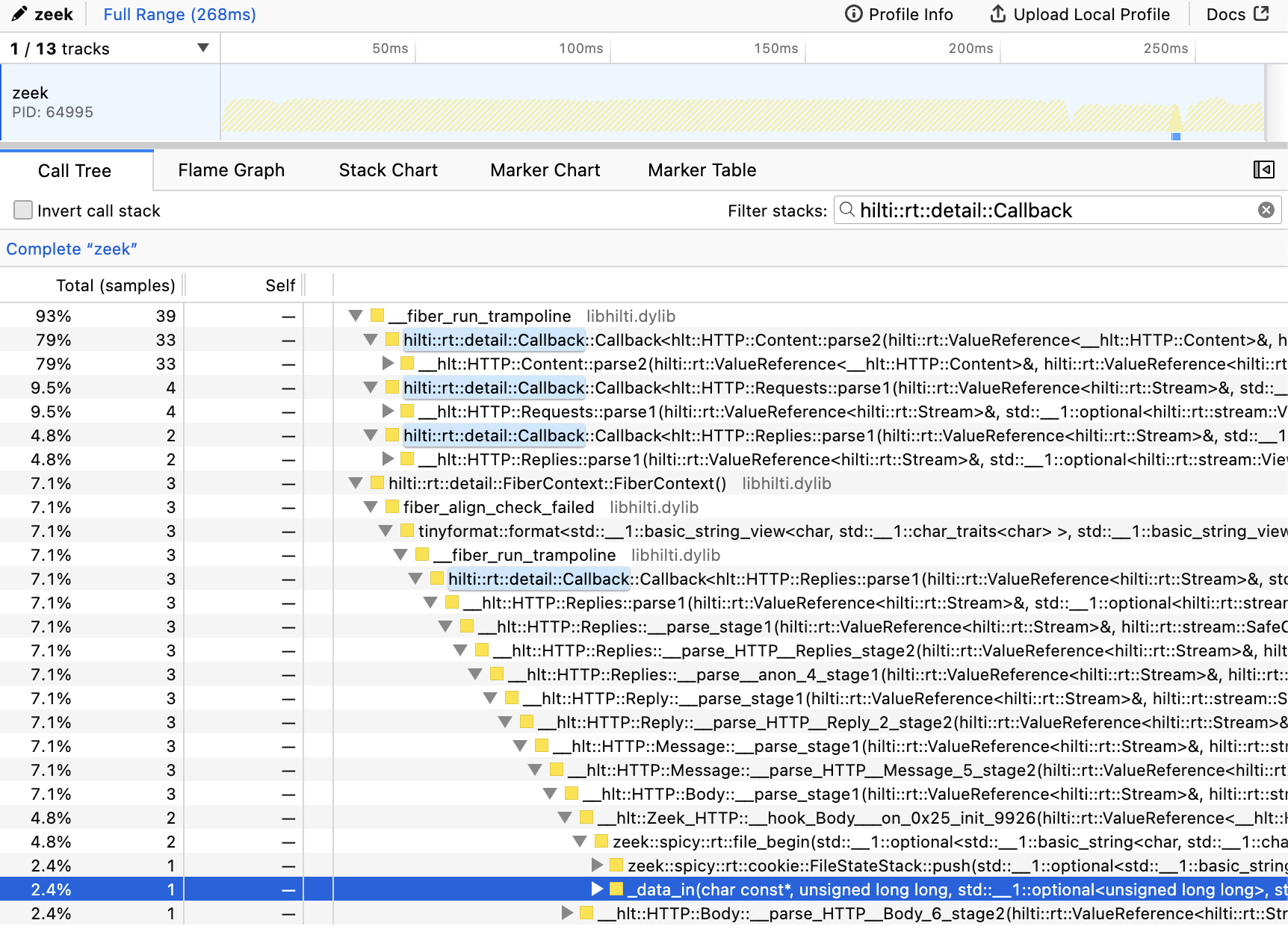
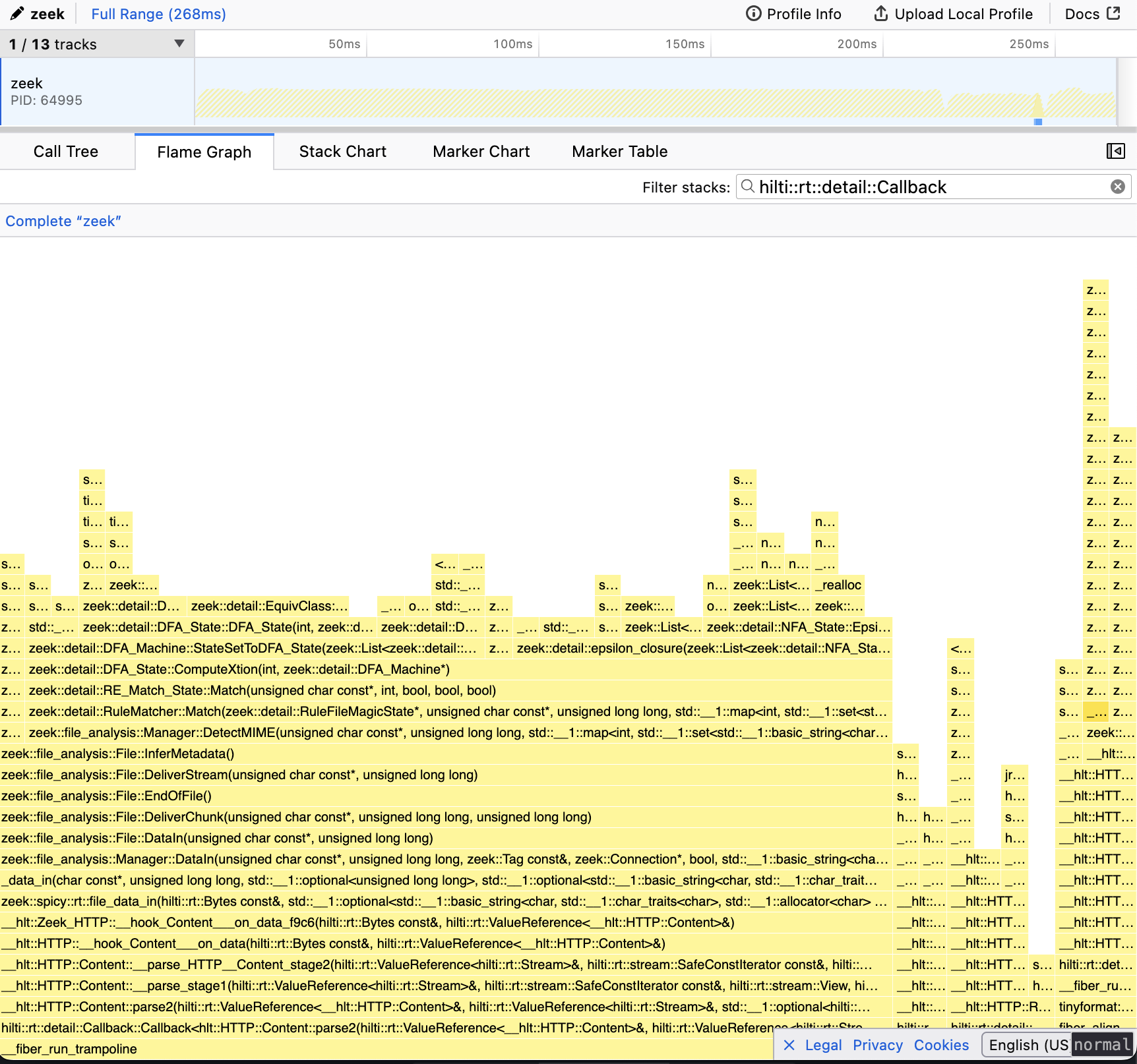
Project: IRC
At this point you should have all the information needed to extract on-wire information via custom parsers and surface it in Zeek for logging (the ultimate goal of most parsing tasks).
The following has a number of tasks around IRC traffic with require combining all needed pieces with less hand holding.
As a general guideline, try to get a working solution first (however ugly), and then dive into cleaning up your implementation (e.g., better parsing, or more targeted or useful events).
You can assume that we are tapping in front of an IRC server which communicates over TCP.
Collect data for channel membership analysis
Create a Zeek log with entries for whenever a user attempts to join a channel (ts, user, channel)
Notes
Zeek already has a builtin IRC analyzer which we need to replace, add the following to your analyzer definition in the EVT file
replaces IRC
Do not call your analyzer or package IRC to avoid name collisions on the
analyzer or Zeek script level.
Sketch of possible solution
There are multiple levels to this:
- create a new analyzer which can parse IRC
JOINinstructions - pass the required information to Zeek via a Zeek event
- create a Zeek log containing the requested information
By searching we can find out that the relevant spec is
RFC1459. Searching the web for a test
PCAP containing this traffic is a little harder, but we can e.g., find a PCAP
with IRC JOIN in the Zeek test suite
here;
if we cannot find existing traffic we could install an IRC client and server on
our own machine and capture the traffic we are trying to parse.
Overall, IRC is a text based format where individual messages are separated by
\r\n; individual message fields for the command and its arguments are
separated by single spaces ``. Every command can start with an optional prefix
identifying the user which can be recognized from starting with :. The JOIN
messages we need to parse have the following format:
[prefix] JOIN <channel>{,<channel>} [<key>{,<key>}]\r\n
A simplistic parser extracting any message could look like this:
module irc;
import spicy;
public type Messages = unit {
: Message[];
};
type Message = unit {
var prefix: optional<bytes>;
var command: bytes;
var args: vector<bytes>;
# For simplicity for now only consume lines and split them manually after
# parsing. "Proper parsing" could be done with e.g., lookahead parsing.
: bytes &until=b"\r\n" &convert=$$.split(b" ") {
assert |$$| >= 2 : ("expected at least 2 parts for IRC message, got %d" % |$$|);
local idx = 0;
# Check for presence of prefix.
if ($$[0].starts_with(b":")) {
# Strip away prefix indicator `:` so we can interpret prefix as a username.
self.prefix = $$[idx].strip(spicy::Side::Left, b":");
++idx;
}
# Due to above `assert` we always have a command.
self.command = $$[idx];
++idx;
self.args = $$.sub(idx, |$$|);
}
};
To get this data into Zeek for logging we could use the following in the EVT file of the analyzer:
on irc::Message if (self.command == b"JOIN") -> event irc::join($conn, self.prefix, self.args.split(b" "));
Even though we have parsed a generic message we can tie it to a Zeek event for
JOIN messages by conditionally raising the event for JOIN messages. This
creates a Zeek event with the signature
event irc::join(c: connection, prefix: string, args: vector of string) {}
where prefix might be an empty string (no prefix present) or contain a
username, and args would need Zeek-side processing to extract the channels
(split first arg at ,).
Zeek: Log very active users
To analyze which users are most active we want to log users which have send more than 5 messages with inter-message-arrival time of less than 5s.
One reason for doing this in Zeek instead of offline would be since it allows performing the analysis without having to store information about all messages.
Notes
This exercise includes a likely small adjustment to the analyzer with most of the needed analysis happening in custom Zeek code.
Sketch of possible solution
The only change needed for the analyzer is that we now also need to surface
PRIVMSG IRC messages. For the analyzer sketched above this could be
accomplished by creating a new Zeek event which is raised for messages with
command PRIVMSG and with a prefix (containing the username).
To collect the needed statistics we could use a Zeek table holding the number
of messages seen per user. By using Zeek's &write_expire we offload removing
less active users, and trigger notices from the event handler if a user's
activity exceeds the threshold.
global user_msg_stats: table[string] of count &default=0 &write_expire=5secs;
event irc::privmsg(prefix: string)
{
# Count this message.
user_msg_stats[prefix] += 1;
# Report if exceeding threshold.
if ( user_msg_stats[prefix] >= 5 )
{
# TODO: Turn this into a notice.
print fmt("user %s is noisy", prefix);
}
}
Sensitive messages
Raise a notice if we see a message which contains any word from a list of trigger words. The notice should contain the username and the message.
- In the first iteration just hardcode the list of words in your Spicy code.
- In the final version we want to declare the list of keywords as a redef'able constant in a Zeek script so it can be changed without having to recompile the analyzer.
Sketch of possible solution
This task can be broken down into 1) detecting whether a seen IRC message and 2) raising a Zeek event for such messages for logging a notice on the Zeek side. On the EVT file this could like this:
# For simplicity we pass the full Message to Zeek, ideally we
# would only transfer required information.
on irc::Message if (zeek_irc::is_sensitive(self)) -> event irc::sensitive_message($conn, self);
Here the task to detect whether the message is "sensitive" is delegated to a
function in the Zeek-specific part of the parser in the analyzer/zeek_*.spicy
file (which by convention can use the Spicy's Zeek API so we can later pull the
list of trigger words from Zeek).
The function might initially look like the following if we followed the parsing approach from the sketch above:
public function is_sensitive(msg: irc::Message): bool {
# As specified only `PRIVMSG` messages can contain sensitive data.
if (msg.command != b"PRIVMSG")
return false;
# TODO: Make this configurable from Zeek.
# NOTE: Using `local` variables for demonstration, a `global` or `const`
# would be clearer and likely also perform better since values
# would only be set once.
local phrases = vector("foo", "bar", "baz");
local num_phrases = |phrases|;
# Assume `args[0]` are the recipients (users or channels), and
# `args[1]` is the message.
for (phrase in phrases) {
if (msg.args[1].find(phrase)[0])
return True;
}
# No sensitive phrase found.
return False;
}
In order to obtain the values from Zeek we could declare a redef'able constant in the Zeek module's export section, e.g.,
const sensitive_phrases = vector("foo", "bar", "baz") &redef;
To get these Zeek values into the Spicy code we could use methods from the
zeek module. With that we would have in the above
local sensitive_phrases: ZeekVector = zeek::get_vector("irc::sensitive_phrases");
local num_phrases: uint64 = zeek::vector_size(sensitive_phrases);
Since phrases are not in a vector anymore but a ZeekVector we would need to
use a different approach to iterate them, e.g., a manually maintained index and
a while loop. To obtain a phrase with the right Spicy type from the
ZeekVector we would use something like to following to match.
local phrase: bytes = zeek::as_string(zeek::vector_index(sensitive_phrases, idx));
Documentation
Community
- Zeek community resources
- Zeek Slack: Feel free to ask anywhere. Many Spicy-specific discussions happen in
#spicy. - Zeek Discourse
- Zeek Slack: Feel free to ask anywhere. Many Spicy-specific discussions happen in